3th job
.
삼성 RPA portal 개선사업 1차, 2차
프로젝트 개요
- automation anywhere(a360) 를 실행시킬 신규 portal 개설 및 기존 데이터 이관
프로젝트 기간
2024.06 - 2025.01
역할
- a360 라이선스 관리
- 라이선스 만료 후 자동 재발급 등
- a360 자격증명 생성 및 관리
- a360 사용자, 역할 그룹 생성 및 관리
- 데이터 이관 쿼리, 프로시져, 배치 작업
- 전용봇(역할 그룹) A360-포털 연계, 배치 작업, 수동(강제) 동기화
- 교육용 A360-포털 연계 데이터 생성, 배치 작업, 수동(강제) 동기화
- 패킷 변조 막기 위한 데이터 암복호화
- 쿠버네티스 주기적 배포
- 결재 및 상신, 알림, 메일 발송 관련 로직 및 템플릿 관리
아키텍쳐

어려웠던 점
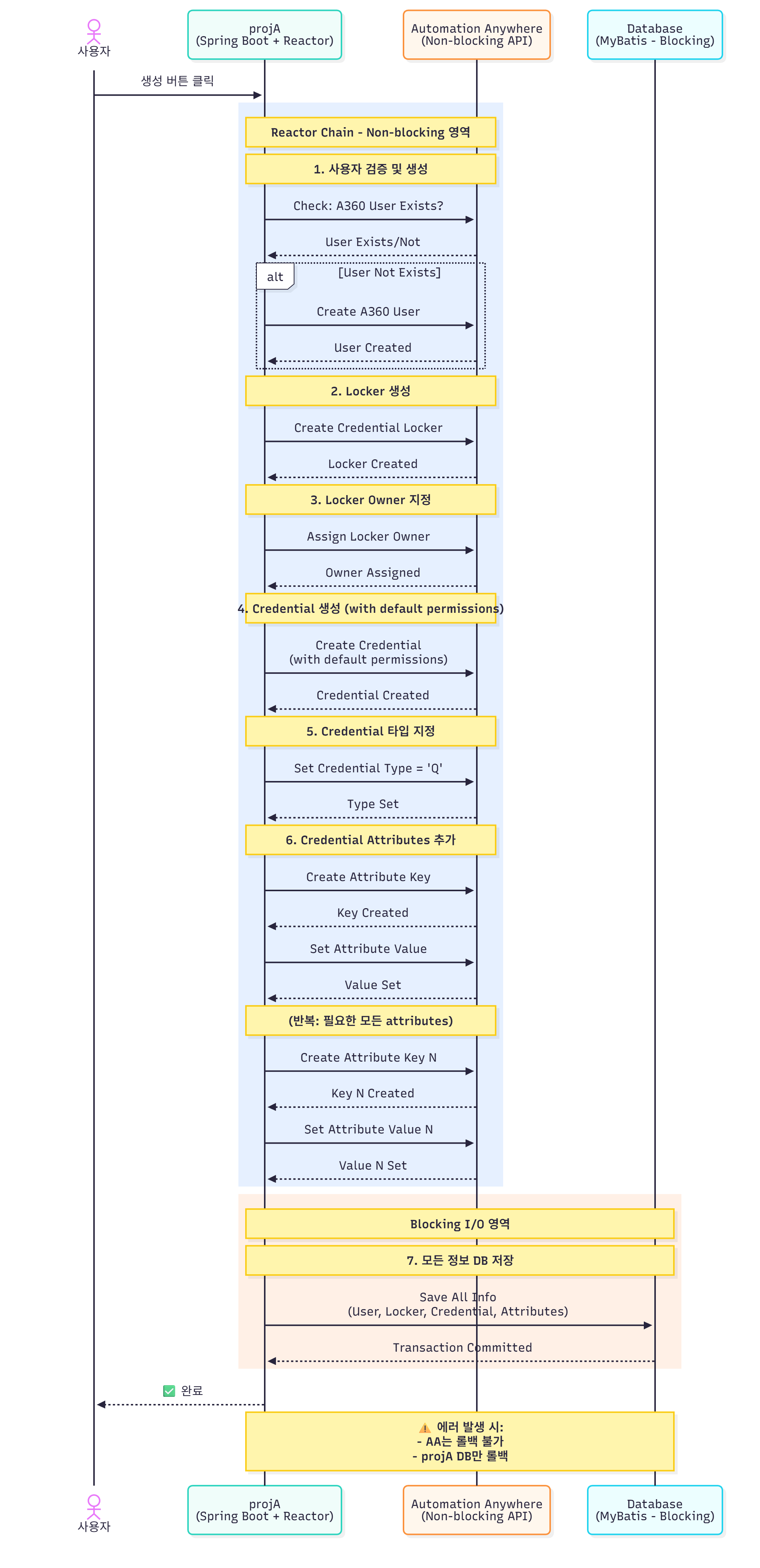
포털을 통해 A360 와 통신하는 데이터 양이 많았기 때문에, 백엔드 로직은 request-callback 패턴으로 구현되었다. 짧게는 5분, 길게는 10분이 걸리는 경우도 있었다. 자동화 프로세스 실행에 엮인 API 가 많아서 오래걸려서 실패하게 되면, 포털에서는 롤백이 되지만 A360 서버에 모든 항목을 롤백 시키기는 어려웠다. 따라서, 현업의 요구에 따라서 오래 걸려도 반드시 프로세스 요청이 종료될 때 까지 기다렸다가 처리해야 했다.
생전 처음 보는 Reactor 라이브러리와 그 생태계를 익히는 것, 다른 개발자가 사용하기 편하게 공통 모듈을 만드는 것 등이 낯설고 어려웠다.
- a360 서버 최신 API 명세서의 부재
- 기존 운영 데이터 LLM 분석 후 업로드하는 과정 중 A서버, B서버를 번갈아가며 통신하는 도중 boundElastic 에러
- backpressure 로 조절
- a360 의 응답이 너무 늦어지는 경우, 포털의 DB connection timeout 문제
- 포털은 비관적 Lock (정합성이 중요), A360 는 낙관적 Lock (version 관리) 에 대한 이해를 바탕으로 트랜잭션 격리, 전파, 롤백 내부 정책 대응
회고
- reactive / event driven / request-callback
- pessimistic lock / optimistic lock
해당 프로젝트는 노후화 된 RPA 포털을 새롭게 구축하는 사업이다. 라이선스가 비싼 솔루션인 automation anywhere 을 권한을 두어 제한하고, 스케쥴링, 모니터링, 운영으로 가기 전 테스트, 결재 및 상신, 라이선스 관리, 동기화, 배치 등의 작업을 구현하는 것이 목표였다.
처음에 설명을 들었을 때는 큰 도전이자 배움의 기회라고 생각했다. 프로젝트 팀장과 함께 메세지 큐(Rabbit MQ) 를 이용한 서버 간 비동기 통신으로 서버가 다운 되더라도 데이터 유실 없이 요청된 작업이 처리될 수 있는 시스템을 만들고자 했다. 프로젝트의 큰 목적이 a360 에 대한 governance 부여와 실시간 모니터링이었기 때문에 나에게는 논리적인 구분인 역할 그룹을 생성하고, 해당 역할 그룹에 속한 사용자, 혹은 사용자 그룹을 기준으로 전체 데이터 flow 를 실행시킬 수 있냐 없냐 여부를 따지는 역할이 주어졌다. 데이터가 (1) RPA 포털, (2) A360, (3) 삼성 내부 연관 데이터 이렇게 3로 분리되어 관리 되었다. 따라서 실시간 동기화, 배치로 주기적 동기화, 강제 전체 동기화 등의 기능도 구현해야 했다.
구현 중 어렵고, 어색했던 점은 Reactor Java 로 구현한 복잡한 데이터 흐름이었다. 예를들면 모든 api 작업은 아래와 유사한 구조로 이루어졌다.
- (RPA) 로그인한 사용자 데이터 & 역할 그룹 생성을 위한 데이터 전송 api
- (A360) 요청을 보낸 사용자가 실제로 존재하는 사용자인지 확인 api & 역할 그룹이 이미 A360 에 존재하는지 여부 체크 api
- (A360) 존재하지 않는 사용자이면, A360 시스템에 사용자를 생성하는 api 요청. 생성 후 RPA 포털에 response
- (RPA) RPA 포털의 데이터베이스에 A360 사용자 ID 업데이트 api & 다시 1번 과정 재개
- (A360) 역할 그룹 생성 api
- (A360) 역할 그룹에 정책으로 정한 권한 등록 api
- (A360) 역할 그룹에 정책으로 정한 사용자, 사용자 그룹 등록 api
- (RPA) 생성된 역할 그룹에 대한 데이터 포털에 등록 api & 알림 전송 api
- (RPA) 위 모든 과정을 이력 테이블에 적재 api
- 만약, 중간에 서버 에러가 발생했다면 A360 서버에 모든 데이터를 역 추적하면서 롤백 api 차례차례 실행
현업이 사용하기에 최대한 불편하지 않게 모든 과정이 백엔드에서 매끄럽게 돌아가야 했다. 트랜잭션은 다른 서버에는 전파되지 않기 때문에, 에러가 발생했을 때 서버 간 데이터의 불일치 문제로 골치가 아팠다. 완전한 성공이라고 판단되기 전까지는, api 의 실행 순서와 결과를 추적하면서 기록했다가 에러 발생 시 쓰레기 데이터가 남지 않도록 처리하는 것이 과제였다. 기존 rpa 포털의 주기적인 데이터 이관, 현업들이 강제로 db 에 밀어넣은 데이터, 배치 과정 중 다른 개발자의 오류 등등으로 개발 단계에서 데이터 불일치 해결을 위해 여러 시행착오를 겪었다.
또한 처음으로 View 테이블 사용의 필요성을 느끼고 사용했다. A360 에서 실질적으로 돌아가는 bot 을 포털에서 조회할 때는 적으면 6개, 많게는 10개의 테이블과의 join 이 필요했다. 모든 쿼리, 서브 쿼리에 join 문이 끔찍하게 많아졌다. 이를 조금이라도 줄이고, 실시간 모니터링 페이지에서도 사용하기 위해서 빈번하게 호출되는 데이터는 View 테이블을 만들어 사용했다. A360 과의 통신 변수 때문에 정확한 시간 측정은 어려웠지만 View 테이블을 사용하고 나서 쿼리 실행이 많이 줄었고 유지 보수 측면에도 이득이 있었다.
가장 난감했던 건 결재, 상신 과정에서의 기존 시스템에서 발생하던 오류였다. 결재 후 유니크한 id 값을 얻어야만 다음 단계 진행이 가능했는데, 기존 결재 시스템의 버그로 id 가 올 때도, 오지 않을 때도 있었다. 해당 로직을 개발한 개발자가 퇴사한지 오래되어 난감했다. 업체에 문의하니 웹소켓 관련 오류일 것 같다는 답변만 들었고 해결책은 전달받지 못 했다. 테스트 결과, 소켓을 오래 열어두고 기다리면 approval id 를 획득할 수 있었다. 따라서 낙관적 업데이트로, id 를 받으면 백그라운드에서 알아서 db 를 업데이트 하도록 처리했다.
처음부터 혼자서 만든건 기존 데이터를 LLM 으로 분석하는 작업이었다. 주기적인 배치와 강제 실행 2가지 api 가 필요했다. 걸림돌은 데이터 양이 엄청 많았다는 점이었다. 이 또한 reactor java 를 이용해 backpressure 를 두어 순차적으로 처리되도록 했다. 중간에 여러 다른 서버에 api 를 날리고, 결과가 올 때까지 대기한 다음 RPA 포털에 데이터를 업데이트 하는 서비스 로직을 생성했다. 모든 기존 데이터에는 엑셀과 파워포인트가 포함되어 있었다. 먼저 엑셀과 파워포인트 파일을 파싱하는 작업, LLM 에 전송해서 분석을 기다리는 작업이 1건당 6분 이상은 걸렸다. 최초로 분석할 as-is 데이터는 1만건이 조금 넘었다. 게다가 시행착오를 겪으며 할 여유도 없었다. 1000건으로 테스트를 해보니, 중간에 자꾸 인증 토큰이 초기화가 되어 삼성 knox 서버, llm 서버 양쪽 연결이 끊어졌기 때문에 이를 해결할 로직도 필요했다. 또한 task 당 토큰 사용량 추적, 내용에서 주로 언급된 키워드를 태그로 추출해서 통계로 뽑기 등의 추가적인 요구사항도 존재했기 때문에 정신이 없었다. 여기에만 모든 시간을 할애할 수 없어 작업 쓰레드를 하나 할당해서, 백그라운드에서 쉴새없이 돌아가도록 했다.
마지막으로 운영에 넘기기 전에는 테이블 40개를 가량을 주기적으로 동기화하는 작업이 필요했다. as-is 가 여전히 사용되고 있었기 때문에, 데이터 유실을 막기 위해서는 배치로 동기화하는 작업이 꼭 필요했다. 테이블 구조와 연관 관계가 설계 시 몇 가지 틀어진 것들이 스노우볼이 되어 이관 쿼리가 굉장히 지저분하고 복잡해졌다. 최초 설계가 얼마나 중요한 지 여실히 느끼는 지옥의 1달 이었다.