1st project
국비교육 이후 - 첫번째 회사
실업급여 카카오 챗봇
프로젝트 개요
- 고용노동부 실업급여 상담 챗봇 운영 및 관리자 페이지
- 실업급여 편람 및 실무자 자료 토대로 엔티티 분류, 머신러닝 용 발화 작성
프로젝트 기간
2022.05 - 2022.11
역할
- 프로젝트 전체 레이아웃 및 공통 컴포넌트 작성
- 카카오 챗봇 api 연동
- 동적 테이블, 차트 용 통계 쿼리 작성
아키텍쳐
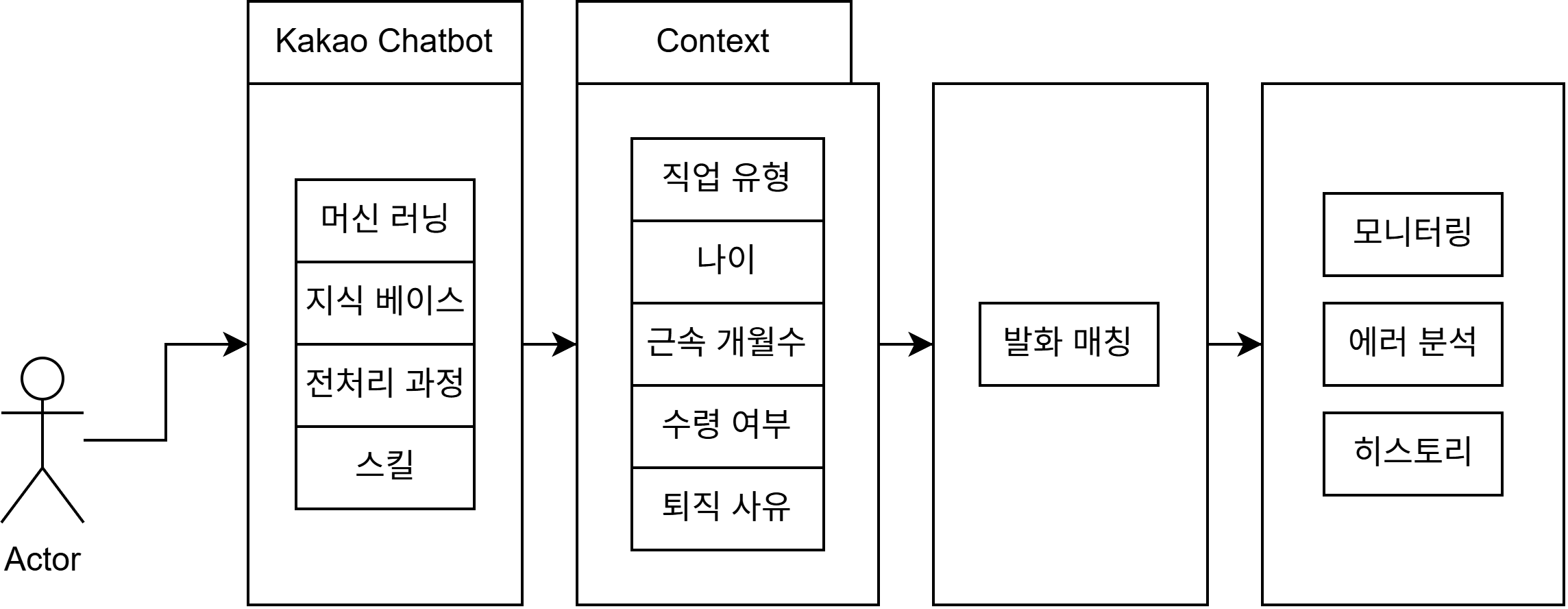
어려웠던 점
- 실업급여에 대한 법, 편람, 기존 상담 사례, 예외 등을 지식을 체계적으로 정리한 뒤, 프로젝트에 녹여내는 작업
- 머신러닝에 필요한 엔티티 추출, 발화문 정리
회고
백엔드만 조금 알고 있던 내게, 들어가자마자 프로젝트 전반적인 레이아웃 및 스타일링 업무가 주어졌다. 출,퇴근 지하철에서 인프런 강의를 보며 css 규칙, flex 개념, keyframe, media-query 등을 학습해서 적용시켰다. 그리고 카카오 챗봇과의 api 연계 후, 실제 카카오톡 대화처럼 웹에서 보일 수 있도록 챗봇과 상담자의 대화를 나타내는 화면을 작업했다. 각각의 말풍선을 클릭하면 다시 세부 정보가 표시되는 등의 작업이 수반됐다. api 라는 것의 개념이 없었지만 풀스택으로 개발하면서 테이블 설계를 토대로 api 를 어떻게 만들어야 좋을 지 고민해보는 좋은 계기였다. 이외에도 수 많은 기준으로 동적인 통계 페이지를 위해서 기나긴 쿼리 작성이 따랐다.
해당 프로젝트에서 가장 남는 것은 개발 대상을 분석하고, 어떻게 테이블로 구조화 시킬 지, 도메인을 어떻게 구성할 지에 대한 고민하는 과정이었다. 실무자가 보는 실업급여 편람 pdf 파일을 7번 정독하며 분석했다. 그리고 관련 법령, 실제 사례, 상담사의 녹취록 등도 분석대상에 포함됐다. 실업급여는 수령이 가능한 대전제 조건을 만족시켜도 세부적으로 받을 수 있는 자격을 논하는 셀 수도 없이 많은 조건이 있다.
글로 적혀있는 개념을 도메인화 시키고, 해당 도메인을 기준으로 비즈니스 로직을 작성하는 과정은 힘들었지만 배우는 점이 많았다. 또한, 도메인을 기준으로 카카오톡 챗봇을 학습시킬 엔티티와 발화문을 뽑는 과정도 순탄지 않았다. 챗봇의 내부적인 동작은 자세히 공개가 되어있지 않았기 때문에, 수 없이 많은 시도를 통해 대략적인 윤곽만 파악한채로 프로젝트가 진행되었다. 데이터가 늘어남에 따라서, 서버의 불안정으로 인해 모든 데이터가 전부 날아가는 등의 사건도 겪었다.
무엇보다, 정말 열심히 분석해서 적용했지만 챗봇이 원하는대로 동작을 안했을 때가 가장 힘들었다. 예를 들어, “제가 n년차 직장인인데요, 예전에 실업급여를 1번 받았는데, 이번 회사도 다니다가 ooo 이유로 그만두게 되었어요. 실업급여 받을 수 있나요?”
이런 발화가 들어온다면
크게는 자영업자인지, 직장인인지 구분해야한다. 그리고 자격요건이 되는지, 고용보험에 가입된 기간을 확인해야 한다. 또한, 비자발적으로 회사를 그만두게되었는지 여부도 물어야 한다. 그리고 가장 중요하게는 본질적인 질문이 무엇인지 묻는것이다. 자격이 되는지를 묻는건지, 금액을 묻는건지, 기간을 묻는건지, 아주 특정한 상황에서 예외가 적용되는 지, 가족이 이러이러한데 되는 지 등등 아주 다양한 케이스가 존재했다. 실질적으로 유의미한 판단을 내리기 위한 조건을 정하고, 해당 정보가 채워질 때 까지 되묻는 방식으로 만들었다. 매끄러운 대화가 이어지려면, A 유저가 가지는 대화의 컨텍스트가 계속 유지되어야 하는데, 이 부분이 어려웠다. 카카오 챗봇 api 문서가 설명하는 것과 실제로 일어나는 현상이 약간 달랐다. 이를 해결하기 위해 카카오 챗봇을 관리하는 카카오 개발팀 직원과 몇 번의 전화 통화도 했지만 큰 소득이 없었다. 내부적으로 어떤 라이프 사이클로 관리되는 지 알 수가 없었다.
애초에 근본적으로 대화의 단위를 나누는 것 부터가 애매함을 프로젝트 중간에 깨닳았다. 공공기관 특성 상 KPI 가 중요한데, 대화의 unit 을 정하지 않고 개발을 시작했다. 여러 합의 끝에 30분 동안을 가장 작은 상담 단위로 정했다. 다만, 여전히 컨텍스트 유지 문제는 해결하지 못 했다. 메뉴얼에 아주 단순하게 적힌 정보를 바탕으로 스크립트를 짜서 확인했지만 내부 소스 코드를 파악하지 않고서야 바운더리, 엣지 케이스 등을 추려낼 수가 없었다.
컨텍스트가, n시간이 지난 후에는 초기화된다 라는 모호한 테스트 결과를 전제로 깔아두고 컨텍스트 유지 테스트를 진행했다. 예를 들어, 사용자가 들어와서 n년차 직장인이고, 강제 지방으로의 장기 출장을 통보 받았을 때 그만 두는 상황이라고 가정하자. 이때 컨텍스트로 유지해야 하는 중점은 직업의 유형, 고용을 유지한 기간, 이전 실업급여를 받은 적이 있는지, 어떤 이유로 그만두는지, 자발적인지 비자발적인지 를 판단의 기준으로 삼았다. 컨텍스트도 내부적으로 계층을 나누었다. 가장 광범위한 정보, 세부적인 정보로 말이다. 그 이후 스크립트로 판단(Java 로 치면 인터셉터) 하여 여러가지 분기를 태운다. 특정 분기점을 통과하면 도달할 수 있는 답변의 바운더리가 정해진다. 그 다음은 머신러닝이 어떤 발화가 가장 가까운지 학습된 결과를 바탕으로 답변을 사용자에게 내보낸다.
실제 사례를 토대로 실업급여 제도 내에서 개념을 여러 layer 로 분리하고, 각 상황에 맞는 발화를 만들어 머신러닝을 시켰음에도 어떨 때는 잘 동작하고, 어떨 때는 전혀 엉뚱한 답을 내놓았다. 아주 미묘한 뉘앙스의 차이인지, 엔티티 구조화의 문제인지, 발화문의 문제인지를 파악하는 것 조차 어려웠다. 오류 상황을 겪고, 다시 엔티티와 발화문을 정제하는 작업이 주를 이뤘다.
오픈 이후에는, 생각보다 많은 데이터에 놀랐고, 금세 db 가 가득차버렸다. 관리자 화면은 너무나 많은 데이터로 먹통이 돼버렸다. 어마어마한 데이터 때문에 사용이 힘들어지자, 각 쿼리의 실행시간을 분석해서 가장 느린 것 부터 뜯어고쳤다. 불필요한 join 을 걷어내며 테이블 구조를 수정하고, 트랜잭션을 분리하는 것이 이득인 경우도 있어 해결에 시간이 꽤 필요했다.
또한 위에서 분류한 엔티티, 발화의 기준에 맞지 않으면 전부 다 에러 케이스로 분류됐다. 해당 에러 케이스에는 욕설, 실업 급여와 전혀 관계없는 발화, 민감한 정보의 요구 등등 내부적인 기준을 정했다. 카카오 챗봇이 제공하는 것 이외에, 별도 기준을 적용하기 위해 전처리 라이브러리를 도입했다.